

Rui Vasconcelos
on 4 November 2020
Deploying Kubeflow everywhere: desktop, edge, and IoT devices
Kubeflow, the ML toolkit on K8s, now fits on your desktop and edge devices! 🚀
Data science workflows on Kubernetes
Kubeflow provides the cloud-native interface between Kubernetes and data science tools: libraries, frameworks, pipelines, and notebooks.
> Read more about what is Kubeflow
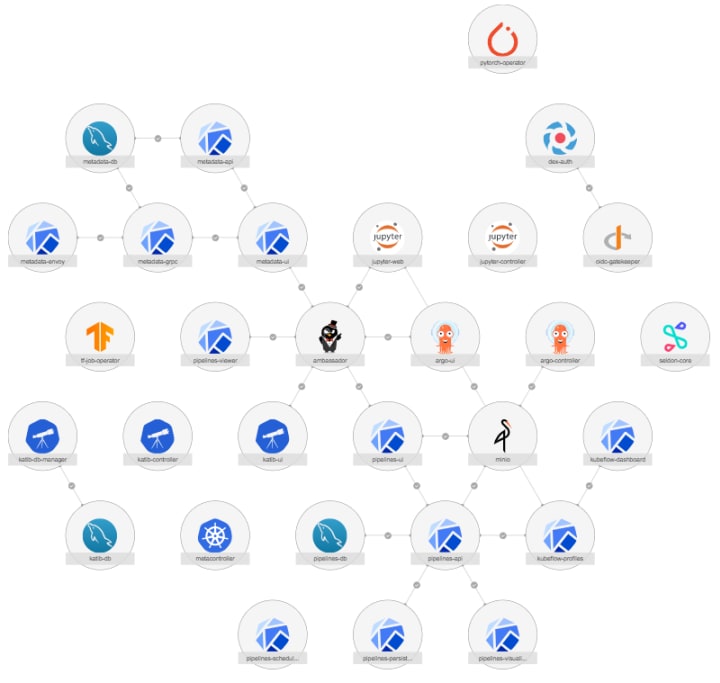
Cloud-native MLOps toolkit gets heavy
To make Kubeflow the standard cloud-native tool for MLOps within the AI landscape, the open-source community has accomplished the aggregation and integration of many projects on top of Kubernetes.
Unfortunately, this notable accomplishment also has a downside. Deploying Kubeflow on your laptop or edge device has become impractical.
The very minimum memory necessary to deploy the full Kubeflow bundle is 12Gb of RAM.
On top of that, it is Linux-based. This means that on Windows and macOS you need to allocate 12+ Gb of memory to a Linux VM.
Last time I tried, my 16Gb of RAM MacBook Pro did not like the idea.
Kubeflow lite to experiment on your desktop: Windows, macOS or Linux
To allow users to conveniently try out Kubeflow directly on their laptops or workstations, Canonical has conveniently pre-selected and packaged a subset of the Kubeflow applications to run on 8Gb of RAM.
Kubeflow runs on top of Kubernetes. Hence, in order to provide an out-of-the-box Kubeflow experience, the underlying K8s had to be also provided in a streamlined way.
The simple way to get K8s with built-in Kubeflow on Windows, macOs or Linux is MicroK8s.
Now, besides the full Kubeflow bundle, MicroK8s also includes a Kubeflow lite bundle. To install Kubelow lite, deploy MicroK8s and then run:
$ KUBEFLOW_BUNDLE=lite microk8s enable kubeflow
> Check out what’s inside Kubeflow-lite
Kubeflow edge for inference and distributed training
Going even smaller in terms of the memory footprint, the Kubeflow edge bundle was born.
Kubeflow edge uses the inference and distributed training pieces inside Kubeflow – including TF-job-operator, PyTorch-operator, Seldon Core and Kubeflow Pipelines – and packages them for a 4Gb of RAM device to run.
So far, we have seen this option generate the most impact in industries that leverage an IoT mesh, such as manufacturing, mobility, retail, or ag-tech.
To install Kubeflow-edge, deploy MicroK8s and then run:
$ KUBEFLOW_BUNDLE=edge microk8s enable kubeflow
> Check out what’s inside Kubeflow edge
DIY: Build your own Kubeflow deployment
With the vision to empower AI innovators leveraging Kubeflow, not constrain them, Canonical has created Kubeflow lite and Kubeflow edge to get you started quickly wherever you are.
Once you have familiarized yourself with all that Kubeflow can offer, you can quickly add any application inside Kubeflow to your current bundle.
You could, for example, start with Kubeflow lite and add Katib the hyperparameter tuning piece of Kubeflow later on. To do this, run:
$ microk8s.juju deploy <app name>
In addition, you can integrate applications that have been deployed with the command:
$ microk8s.juju relate <app A> <app B>
> Check out the list of 60 Kubeflow related applications
Kubeflow operators: the magic behind Kubeflow everywhere
This easy to deploy and composable Kubeflow is only possible due to Charmed Kubeflow, the set of charm operators that wrap the 20+ apps inside upstream Kubeflow.

> Read Kubeflow operators: lifecycle management for data science
Get started with Kubeflow
If you haven’t yet got a taste of Kubeflow, you can follow the upstream Kubeflow workstation docs, or watch the video below:
> Read the docs on MicroK8s Kubeflow add-on for more details.
Further reading
- Canonical launches Kubeflow operators: lifecycle management for data science
- Read Demystifying Kubeflow Pipelines blog series
- Try out Kubeflow with Tutorial: Deploy Kubeflow on Windows, macOS or Ubuntu
- Read Charmed Kubeflow documentation


